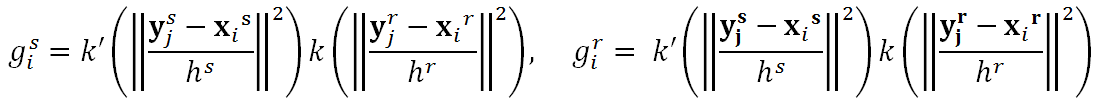Mean Shift Clustering
戻る
概要: Mean Shift法[1]とは,d次元空間内に点群xiが分布しているとき,その密度の極大点(node)を発見する手法である.
より厳密には、点群xiを標本点として出力し得る”確率密度関数”の極大点を発見する手法である.
計算は最急降下法の原理を用いる.
1. 空間内の任意の点を初期位置とし,
2. 徐々に密度(確率密度)の大きな方へ向かって移動して,
3. 極大点(node)に到達すると計算を止める.
点群のクラスタリングや画像の特徴保存フィルタとして応用できる.
[1] Dorin Comaniciu , Peter Meer , Senior Member, Mean shift: A robust approach toward feature space analysis, IEEE Trans. on PAMI, 2002.
カーネル密度推定 Kernel density estimation (準備)
d次元空間にばらまかれたN個の点,x1, x2, ..., xN ∈Rd,を考える.
この点群をある確率分布に従う標本と考えた時,任意の点x∈Rd における確率密度関数f(x)以下の通りである.
...(1)
k(t)は,カーネル関数であり,色々な関数が利用される.
Gaussian カーネル
Rectangular カーネル = 1 \;\;\;\;\;\;\;\;\;\; (|t|<1), \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; 0 \;\;\;\;\;\;\;\;\;\; (other))
Epanechnikovカーネル
ckdは,K(x) = ckdk(||x||2) というK(x)の全体の積分を1にするための,正規化係数.(最終的な計算には使わない)
上の式の説明 :
d次元空間にばらまかれたN個の点,x1, x2, ..., xN ∈Rd,がを考える.
この点群をある確率分布に従う標本と考えた時,任意の点x∈Rd における確率密度関数f(x)は,
Kernel density estimation法により以下のように推定できる.
ここで,H∈Rd×dはバンド幅行列で,K(x)は,有界(値域が有限)、Compact support、正規(定義域全体での積分が1)、対称、指数関数減衰の条件を満たすカーネルである.
実用的には,バンド幅行列H=diag(h2,h2,...h2)とする事が多い.h∈Rはバンド幅パラメータ.
すると、点xの確率密度関数f(x)は,以下の通り.
さらに,ベクトル値を引数に取るカーネルK(x)は,スカラー値を引数に取るk(t)を用いて次のように表す事が多い.
こうすると,自然にK(x)の放射対称性が満たされる.ckdは,K(x)の正規性を満たすための係数である.
以上より,上の式(1)を得る.
カーネル密度関数f(x)の微分(準備2)
式(1)の勾配は以下の通りである.
これは以下の通り変形できる.
ただし,
と置いた.(k'はkをtで偏微分)
さらに,
...(2)
この形が後々重要.
式変形の過程で,Σgi>0 を仮定した.これは前述のGaussianカーネルとかEpanechnikovカーネルを使っていれば満たされる.
特に説明することもないけど,よく利用される以下の公式を使った.ボールドxは,d次元ベクトル.
Mean Shift Procedure
d次元空間RdにばらまかれたN個の点,x1, x2, ..., xN ∈Rd,と,任意の点y∈Rdについて,
点y付近の点群密度の極大点(node)は,次の通り求められる.
1. 初期化 y0 ← y
2. 更新(Mean Shift)ただし
3. ||yi+1-yi|| < threshold となるまで2.を繰り返す
4. 収束したらその yiを出力
説明.
式(2)は非常に重要な形をしている.
まず、前半は,GaussianカーネルやEpanechnikovカーネルを用いた場合,正になる.
後半は,Mean Shiftと呼ばれる項で,点xの近傍のデータ点群の加重平均位置とx自身の差分ベクトルである.
a1) このMean Shiftベクトルが,▽f(yt)の方向を表す.
a2) このMean Shiftベクトルは,方向だけでなく、長さも内包している.つまり,極大点から遠い点ではMean Shiftベクトルは大きくなり,
計算が進み,ytが極大点に近づいてくると,Mean Shiftベクトルは徐々に小さくなる.
最急降下法を使えば,次の通りyiを更新できる.
 )
ただし、hはタイムステップ.ここで(a1)を踏まえると,
となる.さらに(a2)の長さを内包していることに注目すると h = 1として良い(一番問題になるオーバーシュートが起きない)ので、
上のアルゴリズム中のMean Shiftの更新と同じものが得られた.
Mean Shift Clustering
Mean Shift Procedure algorithmはクラスタリングにおうよう出来る.
d次元空間RdにばらまかれたN個の点,x1, x2, ..., xN ∈Rd,が入力された下で.
密に分布する点群をクラスタとして分割する.
1. 各点xi にMean Shift Proceduerを適用し,収束位置xic を計算する
2. 任意の2個の点 xi xk について,その収束位置が閾値以下なら,( ||xic - xkc|| < thresh )この二点を同じクラスタに入れる.
これにより,同じ密度の極大点(node)に属する点群が同じクラスタになるよう,分割できる.
上の手法は,入力点群全てに対してMean Shiftを計算するので,計算コストが高い.
計算コスト削減のための,下のような手法もある.
1. d次元空間のデータ点群の分布する全体を覆う十分密な初期点群 yi を用意する.
2. yi 全てにMean Shift Procedureを適用し収束点 yicを計算する.
3. 十分近い収束点を持つyiに同じラベルを付加する.
4. yiは空間全体を覆う点群なので,すべてのyiのMean shift procedure計算時に少なくとも1つのカーネルがxiを訪れている.
xiに,xiを訪れたカーネルのラベルを付加する.
異なるnodeへ収束する複数カーネルがxiを訪れた時は,多数決でラベルを決定する.
(でも,xiより少ない数で空間全体を覆う点群yiの構築は結構大変そう.)
k-means clusteringが,クラス多数を入力として必要とするのに対し.
Mean Shift Clusteringは,クラス多数の情報なしに,点群の粗密を解析しクラスタ分割を行える.
Mean Shift Image Filtering
Mean Shift Proceduerを利用すると,エッジを保存する画像の平滑化が行える.
1. カラー画像 I , 画素位置に関するバンド幅hs, 画素値に関するバンド幅hr を入力とする.
2. 画素 xiは,その位置 (xi,yi) と 画素値 (Li, ui, vi) を結合した,
画素位置-画素値-結合空間 (Bilateral Domain)内の点pi (xi,yi, Li, ui, vi) であると考える.
全ての画素 xi について, そのBilateral Domain内の点piを計算しておく (5次元ベクトルにしておく)
3. 全てのpi にMean Shift Proceduerを計算し,収束位置をpic = (xic,yic, Lic, uic, vic)とする.
4. xiの画素値を, (Lic, uic, vic) で置き換える.
○Mean Shift Proceduerは次の通り計算する○
xs, xrをそれぞれ、5次元ベクトルの位置(2D)・色(3D)空間に対応するものとし,カーネル密度推定を以下の通り定義する.
Mean Shiftにより、次の通り位置を更新する. (勾配の求め方は前述の通り)
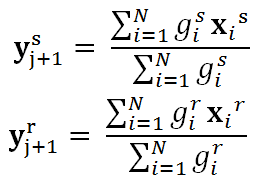
ただし
Mean Shift Image Filteringの結果 k(t) = 1-|t|を利用

Original hs = 8, hr = 8

hs = 32, hr = 8 hs = 32, hr = 32